
ARTICLE
In the ever-evolving world of software development, understanding architectural patterns is crucial for designing robust, scalable, and maintainable applications. These patterns offer reusable solutions to common problems in software architecture, providing a foundation for developers to build upon. In this article, we’ll dive deep into 10 of the most common software architectural patterns, explore their use cases, and analyze their pros and cons. Whether you're an intermediate developer refining your skills or a seasoned professional seeking a refresher, this guide is tailored to you.

Software Architectural Patterns
What Are Software Architectural Patterns?
An architectural pattern is a general, reusable solution to a commonly occurring problem in software architecture within a given context. Unlike design patterns that are concerned with specific implementation details, architectural patterns operate at a higher level, focusing on the structure and behavior of entire systems.
By mastering these patterns, developers can:
- Improve code organization and maintainability.
- Enhance scalability and performance.
- Reduce development time by leveraging proven solutions.
Let’s explore these patterns in detail, accompanied by examples and real-world applications.
Layered Pattern
The Layered Pattern, also known as the n-tier architecture, is a systematic approach to organizing software into logical layers. Each layer is responsible for a specific set of tasks and interacts with adjacent layers in a predefined manner. This separation of concerns enables developers to isolate functionality, making the system easier to develop, test, and maintain.
Typically, the layered architecture consists of the following core layers:
- Presentation Layer (User Interface): This layer handles user interactions and displays information. It is focused on delivering a seamless user experience.
- Application Layer (Business Logic): This layer implements the core business logic and processes user requests. It acts as the intermediary between the presentation and data layers.
- Data Access Layer (Persistence): This layer manages data storage and retrieval, interacting directly with databases or other storage systems.
- Database Layer: This layer is responsible for the physical storage and organization of data in a database.
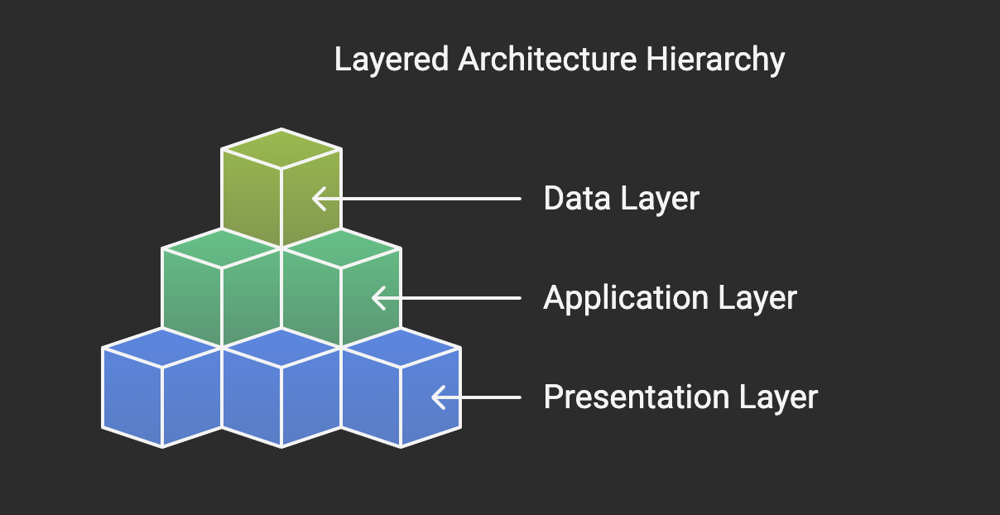
Layered Pattern
Depending on the complexity of the application, additional layers such as a service layer or a security layer may also be included.
Benefits of the Layered Architecture
The layered architectural pattern is popular for good reason. Here are some of its key advantages:
- Separation of Concerns: Each layer is responsible for a specific aspect of the application, making it easier to develop and maintain.
- Scalability: Layers can be scaled independently, allowing for more efficient resource allocation.
- Reusability: Components within a layer can often be reused across different applications or projects.
- Ease of Testing: Isolated layers ensure that testing can be performed in a modular manner, reducing complexity and improving test coverage.
- Flexibility: Changes in one layer (e.g., UI redesign) typically do not require changes in other layers, allowing for greater adaptability.
Use Cases:
- E-commerce Platforms: In an online shopping application, the presentation layer might display product catalogs, while the business logic layer handles order processing, and the data layer manages inventory information.
- Enterprise Applications: Many enterprise systems, such as customer relationship management (CRM) software, rely on layered architectures to separate user interfaces, business rules, and data management.
- Web Applications: Frameworks like ASP.NET and Spring MVC often implement the layered pattern to structure web applications.
Pros:
- Clear separation of concerns.
- Easy to test and maintain.
- Suitable for large-scale applications with multiple developers.
Cons:
- Performance overhead due to layer-to-layer communication.
- Not ideal for real-time, low-latency systems.
Example:
// Example of Layered Architecture in Java
public class UserService {
private UserRepository userRepository;
public User getUserById(int id) {
return userRepository.findById(id);
}
}The layered software architectural pattern remains a cornerstone of modern software design. Its emphasis on modularity, separation of concerns, and scalability makes it an ideal choice for a wide range of applications. However, like any architectural approach, it must be applied thoughtfully, with careful consideration of the specific requirements and constraints of the project.
Client-Server Pattern
At its core, the client-server architecture is a system design pattern that divides responsibilities between two key entities: the client and the server. The client is responsible for initiating requests, while the server handles these requests and provides the necessary responses or services. This division of labor allows for a modular and scalable approach to application development.
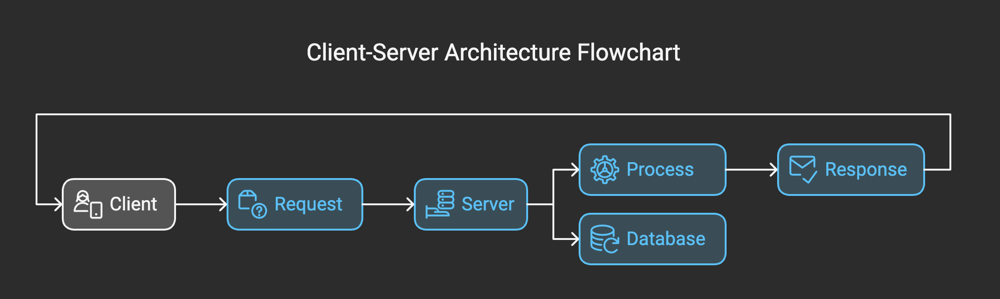
Client-Server Pattern
The architecture enables a clear separation of concerns:
- The client focuses on user interaction and presentation.
- The server manages data storage, business logic, and processing.
This design can be applied to a wide range of applications, from simple desktop software to complex web and mobile systems.
Key Components of the Client-Server Architecture
- Client: The client is the front-end component that interacts with the user. It could be a web browser, a desktop application, or a mobile app. The client sends requests to the server, seeking specific services or data, and displays the results to the user.
- Server: The server acts as the back-end component, responsible for handling client requests. It performs tasks such as retrieving data from a database, executing business logic, or managing computational workloads. The server may also enforce security protocols and ensure data consistency.
- Communication Protocols: The interaction between the client and server is facilitated through communication protocols, such as HTTP, TCP/IP, or WebSocket. These protocols standardize the way data is formatted and transmitted between the two entities.
Advantages of the Client-Server Architecture
- Scalability: Servers can be upgraded or replicated to handle increased loads, enabling the system to scale as demand grows.
- Centralized Management: Data and resources are stored centrally, making it easier to enforce security, perform maintenance, and ensure consistency.
- Flexibility: Clients and servers can be developed independently, allowing for diverse technologies and platforms to coexist.
- User Experience: Clients can offer rich, interactive interfaces tailored to user needs.
Use Cases:
- Email systems (e.g., Gmail, Outlook).
- Online banking applications.
Pros:
- Centralized control and management.
- Scalability via server upgrades.
Cons:
- Dependency on server availability.
- Potentially high server loads during peak times.
The client-server software architectural pattern has stood the test of time, evolving alongside the technological landscape. Its ability to adapt to different scenarios, combined with the clarity it brings to system design, ensures its continued relevance. Whether you're building a simple application or a complex distributed system, understanding and leveraging the client-server architecture is an essential skill for any software developer.
Master-Slave Pattern
The Master-Slave pattern is a distributed software architecture in which a central "master" component delegates tasks to one or more "slave" components. The slaves execute these tasks independently and return the results to the master, which then consolidates the outcomes to produce a final result or make decisions.
This architectural pattern mirrors real-world hierarchies, where a central authority delegates work to subordinates. It is commonly used in systems requiring workload distribution, synchronization, or redundancy, such as databases, parallel computing, and control systems.
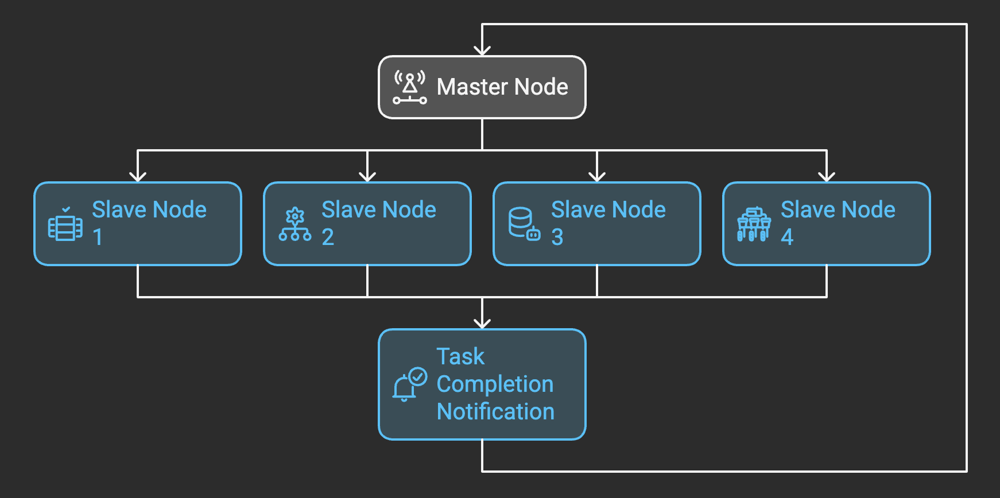
Master-Slave Pattern
Core Structure of the Pattern
The Master-Slave pattern can be broken down into the following components:
The Master:
- Acts as the orchestrator.
- Assigns tasks to slaves based on specific logic, such as workload, availability, or priority.
- Aggregates results from slaves to produce a final output.
- Handles error recovery or retries when tasks fail.
The Slaves:
- Perform the tasks assigned by the master.
- Operate independently, often without knowledge of one another.
- Report outcomes (success, failure, or data) back to the master.
Communication Mechanism:
- Facilitates interaction between the master and slaves.
- Can rely on messaging systems, APIs, or other forms of communication depending on system requirements.
Shared Resources (Optional):
- In some implementations, slaves may rely on shared data or resources, requiring synchronization mechanisms to prevent conflicts.
Use Cases:
- Database Replication: In database systems, the master node handles writes and updates, while read requests are distributed to replicated slave nodes to balance the load.
- Parallel Computing: Computational problems are divided into smaller sub-problems, processed concurrently by multiple slaves, and then aggregated by the master.
- Robotics and Control Systems: In robotics, the master controller delegates specific tasks (like limb movements) to slave controllers, ensuring precise coordination.
- Search Engines: Slaves index and search subsets of data, while the master consolidates results to provide users with accurate outputs.
With the advent of cloud computing, microservices, and distributed systems, the Master-Slave pattern has evolved. Modern systems often incorporate elements of this pattern but adapt it to suit contemporary requirements. For example, leader-follower or worker-queue patterns are variations that address some of the limitations of the traditional Master-Slave model.
In cloud environments, technologies like Apache Hadoop use a similar concept in their MapReduce framework, where a master node coordinates the execution of distributed tasks among worker nodes.
Pros:
- Parallel processing improves performance.
- Fault tolerance if slaves are replicated.
Cons:
- Single point of failure in the master.
- Complex synchronization mechanisms.
The Master-Slave software architectural pattern remains a timeless solution for systems requiring task delegation, parallelism, and fault tolerance. Its simplicity, scalability, and efficiency have made it a go-to choice for a wide array of applications, from databases to robotics.
Pipe-Filter Pattern
The Pipe-Filter pattern is a stream-based software architecture that structures an application as a series of components called filters, connected by communication channels known as pipes. Each filter performs a specific transformation or computation on the data it receives before passing the output to the next stage through a pipe.
This pattern is inspired by the Unix philosophy, where small, composable programs are chained together through pipelines to perform complex tasks. Its modular nature makes it an excellent choice for systems that require flexibility and reusability.
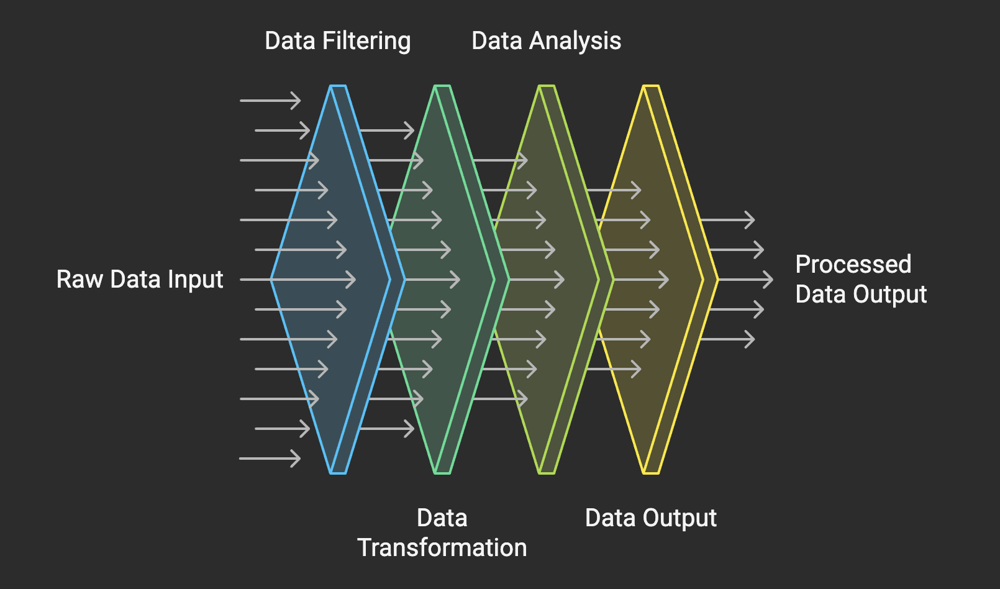
Pipe-Filter Pattern
Core Structure of the Pattern
At its core, the Pipe-Filter pattern is composed of two primary elements: filters and pipes.
Filters:
- Filters are the independent processing units in the system.
- Each filter performs a well-defined operation, such as data validation, transformation, or aggregation.
- Filters are designed to be stateless, meaning they do not retain information between executions. This ensures their reusability and simplifies testing.
Pipes:
- Pipes act as communication channels between filters.
- They transfer the output of one filter to the input of the next, maintaining a unidirectional flow of data.
- Pipes can take various forms—files, in-memory buffers, message queues, or streams—depending on the system's requirements.
Data Flow:
- Data flows sequentially through the pipeline, starting from an initial input source, passing through multiple filters, and ending at an output destination.
Use Cases:
- Data Processing Systems: Systems that process large volumes of data, such as ETL (Extract, Transform, Load) pipelines, frequently use the Pipe-Filter pattern. Data is extracted from a source, transformed through a series of filters, and loaded into a target system.
- Compilers: Compilers often adopt this pattern by dividing the compilation process into phases like lexical analysis, syntax analysis, semantic analysis, optimization, and code generation, each handled by a separate filter.
- Image Processing: Many image processing tools use pipelines where filters perform operations like resizing, color adjustment, and noise reduction sequentially.
- Streaming Applications: Applications like media streaming or real-time analytics process continuous streams of data through filters that handle decoding, parsing, and analysis.
- Command-Line Tools: Unix-based command-line utilities exemplify the Pipe-Filter pattern, where commands like grep, sort, and awk are chained together using pipes to process text data.
Pros:
- Modular and reusable filter components.
- Easy to scale by adding more filters.
Cons:
- Increased latency due to pipeline processing.
- Debugging a pipeline can be challenging.
Broker Pattern
The Broker architectural pattern is a structural design pattern used in distributed systems to mediate communication between clients and services (or servers). In this pattern, a Broker component acts as an intermediary, coordinating requests from clients and responses from servers. By decoupling these entities, the pattern ensures that neither the client nor the server needs to know the intricate details of the other's implementation.
This approach is particularly useful in systems where multiple components distributed across a network need to interact seamlessly. For instance, consider a system with different services written in various programming languages, running on disparate platforms. The Broker abstracts away these complexities, enabling a unified and efficient communication flow.
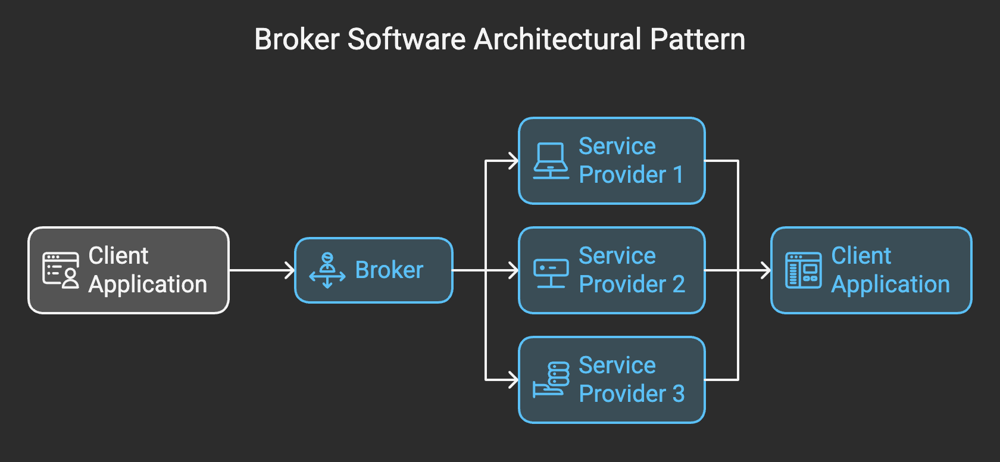
Broker Pattern
Key Components of the Broker Pattern
The Broker pattern relies on several core components, each playing a specific role in the system's functioning:
- Client: The entity that initiates requests. Clients interact with the Broker to access services without needing to know their exact location or implementation details.
- Broker: The central component that manages communication between clients and services. It handles tasks such as:
- Locating the appropriate service
- Forwarding client requests to the service
- Relaying responses back to the client
- Server (or Service Provider): The entity that provides the functionality requested by the client. Servers register themselves with the Broker, making their services discoverable.
- Stub/Proxy: These are client-side or server-side abstractions that hide the underlying communication details. Stubs simplify the process of invoking remote services by acting as local representatives.
- Registry: A database or directory maintained by the Broker, storing metadata about available services, their locations, and how to access them.
Use Cases:
The Broker architectural pattern is widely used in scenarios where distributed components need to interact. Some common use cases include:
- Middleware Systems: Many middleware platforms, such as CORBA (Common Object Request Broker Architecture), are based on the Broker pattern. These systems facilitate communication between distributed objects.
- Message Brokers: Messaging systems like RabbitMQ and Apache Kafka use the Broker concept to route messages between producers and consumers.
- Remote Procedure Calls (RPC): Frameworks like Java RMI and .NET Remoting rely on the Broker pattern to enable remote method invocation.
- Microservices and SOA: In service-oriented architectures (SOA) and microservices, the Broker pattern is often used to mediate interactions between loosely coupled services.
Pros:
- Decouples components for better scalability.
- Flexibility to switch or upgrade individual components.
Cons:
- Performance bottleneck if the broker is overloaded.
- Complex configuration and setup.
The Broker architectural pattern remains a cornerstone of distributed system design, providing a structured approach to managing communication between clients and services. Its ability to decouple components, support scalability, and facilitate interoperability makes it an invaluable tool for software architects.
However, like any architectural pattern, it is not a one-size-fits-all solution. Developers must carefully evaluate their system's requirements and constraints before adopting the Broker pattern. When implemented effectively, it can lead to systems that are not only functional but also scalable, maintainable, and future-proof.
Peer-to-Peer Pattern
At its core, Peer-to-Peer architecture is a decentralized model where each participating device, known as a "peer," acts as both a client and a server. Unlike traditional client-server architectures, where a central server handles requests and distributes resources, P2P systems distribute responsibility across all participants. This eliminates the need for a central authority, enabling direct communication and resource sharing between peers.
P2P architecture is not a new concept. Its roots can be traced back to the early days of computer networking, but it gained widespread popularity with the advent of file-sharing systems like Napster, BitTorrent, and Gnutella. Today, P2P continues to power various systems, including blockchain networks, distributed file storage, and even modern communication platforms.
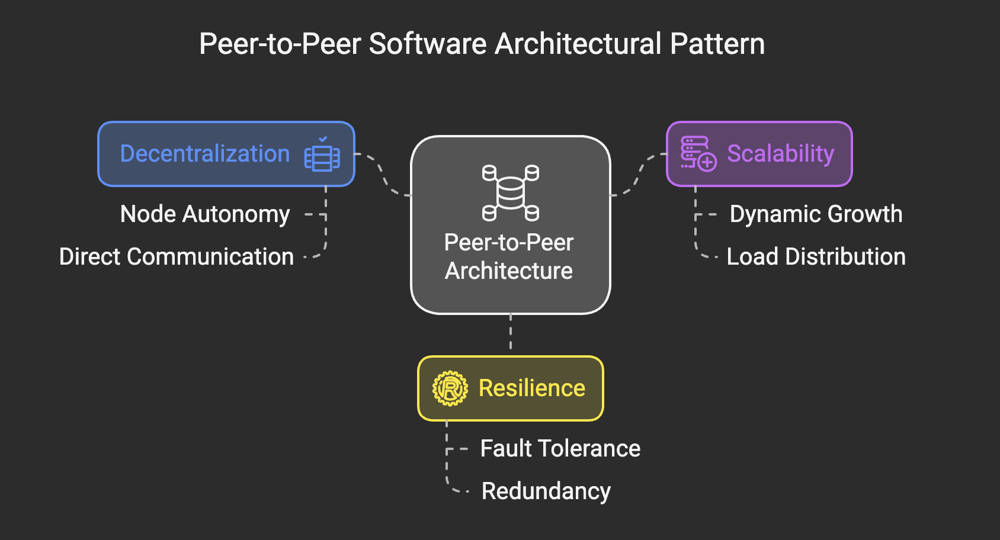
Peer-to-Peer Pattern
Key Characteristics of Peer-to-Peer Architecture
- Decentralization: In P2P systems, there is no single point of control or failure. Every peer is autonomous and contributes to the overall functionality of the network. This makes the system robust and highly resilient to failures.
- Scalability: Adding new peers to a P2P network increases its capacity and computing power. Unlike client-server systems, where scalability often requires extensive infrastructure upgrades, P2P networks naturally grow as more participants join.
- Fault Tolerance: Since data and resources are distributed across multiple peers, the failure of a single node has minimal impact on the system. This redundancy ensures that the network remains operational even in adverse conditions.
- Direct Communication: Peers can communicate directly with one another. This removes the bottleneck associated with central servers and improves the speed and efficiency of data exchange.
- Resource Sharing: P2P networks rely on the collective resources of all participants. Each peer contributes its bandwidth, storage, or computational power to the network, creating a collaborative ecosystem.
Types of Peer-to-Peer Architectures
There are several variations of P2P architecture, each designed to address specific requirements and use cases.
- Pure P2P: In a pure P2P system, every peer is equal and has the same responsibilities. There is no central coordinator or hierarchy. Examples include early file-sharing systems like Gnutella.
- Hybrid P2P: Hybrid P2P systems introduce a central component to improve efficiency or manage specific tasks. For example, some systems use a central server for peer discovery, but once connections are established, communication occurs directly between peers. BitTorrent is a notable example of this approach.
- Structured P2P: These systems organize peers in a structured manner, often using distributed hash tables (DHTs) to enable efficient resource lookup. Chord and Kademlia are popular structured P2P protocols.
- Unstructured P2P: In unstructured P2P networks, peers do not follow a predefined topology. Instead, they connect arbitrarily, making resource discovery more challenging but also more flexible. Gnutella is an example of an unstructured P2P network.
Use Cases:
P2P architecture has found applications in a wide range of domains, often pushing the boundaries of what distributed systems can achieve.
- File Sharing: Early pioneers of P2P technology, like Napster and LimeWire, revolutionized the way users shared files. Modern platforms like BitTorrent continue to thrive, enabling efficient distribution of large files.
- Blockchain and Cryptocurrencies: Blockchain networks, the foundation of cryptocurrencies like Bitcoin and Ethereum, rely heavily on P2P architecture. Each participant (node) in the network validates transactions and maintains a copy of the distributed ledger.
- Distributed Storage: Systems like IPFS (InterPlanetary File System) use P2P architecture to create decentralized storage solutions. Files are broken into chunks, distributed across peers, and retrieved using unique content identifiers.
- Online Gaming: Multiplayer online games often leverage P2P networks for real-time communication and data exchange between players. This reduces latency and improves the gaming experience.
- Video Conferencing: Some video conferencing platforms utilize P2P connections to establish direct links between participants, reducing reliance on central servers and lowering costs.
- Edge Computing: P2P principles are increasingly being adopted in edge computing, where devices at the network's edge collaborate to process and share data without relying on centralized cloud services.
As technology evolves, the role of P2P architecture continues to expand. Emerging trends like decentralized finance (DeFi), Web3, and distributed AI processing are heavily reliant on P2P principles. Moreover, the growing demand for privacy and autonomy in digital systems is driving renewed interest in decentralized solutions.
Pros:
- High fault tolerance due to decentralized architecture.
- Scales well with the number of peers.
Cons:
- Security vulnerabilities in open networks.
- Hard to manage and monitor.
Peer-to-Peer software architectural patterns represent a paradigm shift from centralized systems to decentralized, collaborative networks. By leveraging the collective power of individual peers, P2P systems offer unparalleled scalability, resilience, and flexibility. While challenges remain, the growing adoption of P2P in diverse domains highlights its enduring significance in the software landscape.
Event-Bus Pattern
At its core, the Event-Bus pattern is a messaging architecture that facilitates communication between different components of a software system through the use of events. Instead of components directly calling each other, they communicate indirectly via a centralized hub or "bus." The event bus serves as the backbone of the system, routing events from producers (publishers) to consumers (subscribers) who are interested in those events.
This pattern promotes loose coupling by ensuring that components are unaware of each other's existence. Instead, they only need to know how to publish or subscribe to events on the bus, which reduces dependencies and fosters modularity.
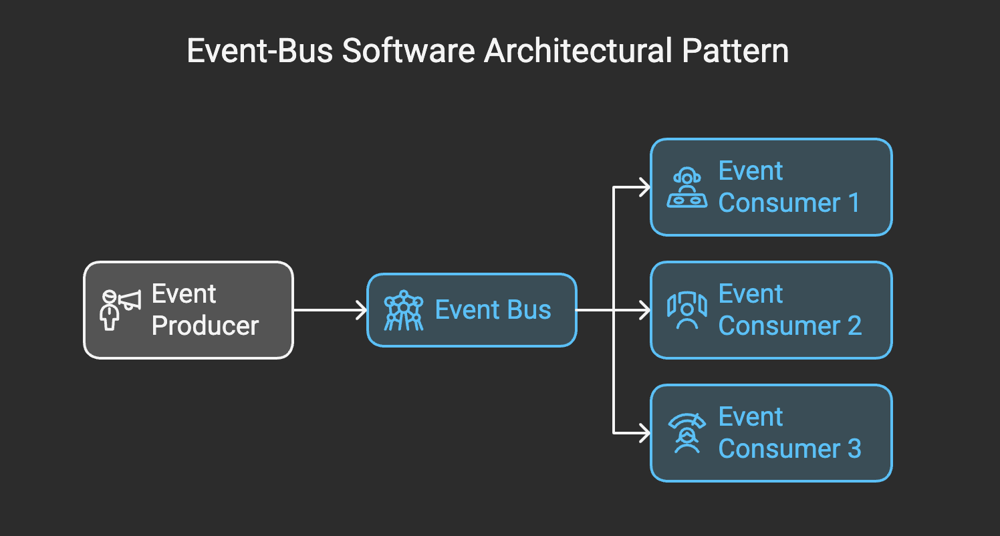
Event-Bus Pattern
How the Event-Bus Pattern Works
To better understand the mechanics of the Event-Bus pattern, let’s break it down into its key components:
- Event Producers (Publishers): These are the components or services that generate events. For example, in a retail application, a payment service might publish an event like
OrderPaid. - Event Consumers (Subscribers): These components react to specific events. For instance, an inventory service might subscribe to the
OrderPaidevent to decrease stock levels accordingly. - Event Bus: The event bus acts as the intermediary. It receives events from producers and forwards them to all relevant consumers. It may also include additional features like filtering, prioritization, and message persistence depending on the implementation.
- Events: Events are lightweight messages that represent a specific occurrence or change in the system. They typically contain minimal data, such as IDs or metadata, that consumers can use for further processing.
A simple flow might look like this:
- A user places an order.
- The order service publishes an
- The payment service subscribes to
- Once the payment is successful, the payment service publishes an
- Multiple services, like inventory, notification, and analytics, subscribe to
Use Cases:
The Event-Bus architectural pattern is widely used in various domains and applications, including:
- Microservices Architecture: In a system with many loosely coupled services, the Event-Bus pattern facilitates seamless communication between them.
- Event-Driven Systems: Applications that rely on real-time updates, such as chat applications, stock trading platforms, or IoT systems, benefit from the responsiveness of event-driven patterns.
- Data Processing Pipelines: Events can trigger different stages of data processing, allowing for dynamic workflows.
- Domain-Driven Design (DDD): In DDD, events can represent domain-specific occurrences, making the Event-Bus pattern a natural fit.
Pros:
- Loose coupling between components.
- Easy to extend by adding new events.
Cons:
- Difficult to debug event-driven systems.
- Risk of bottlenecks in high-frequency event systems.
The Event-Bus software architectural pattern is a powerful tool for designing decoupled, scalable, and extensible systems. By abstracting communication between components and enabling asynchronous, event-driven workflows, it empowers developers to build resilient and responsive applications. However, like any architectural choice, it requires careful consideration of trade-offs, including complexity and performance implications.
When implemented effectively, the Event-Bus pattern can transform the way systems handle communication, enabling them to thrive in today’s fast-paced, interconnected digital world. Whether you're building microservices, data pipelines, or real-time applications, the Event-Bus pattern is worth exploring as a cornerstone of your architecture.
Model-View-Controller (MVC) Pattern
The Model-View-Controller pattern is a design paradigm that divides an application into three interconnected components: the Model, the View, and the Controller. Each component has a distinct responsibility, which ensures a clean separation of concerns. This separation makes it easier to manage complex systems, especially those with multiple developers working on different parts of the application.
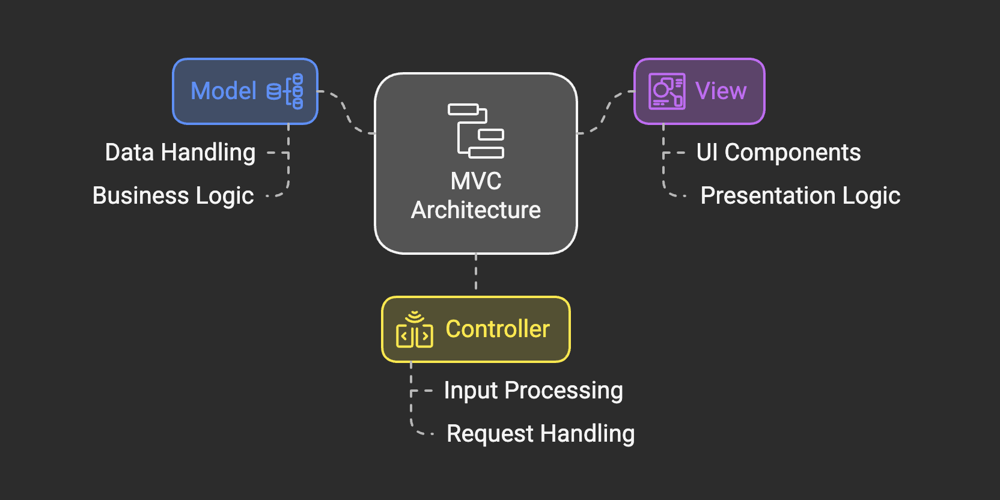
Model-View-Controller (MVC) Pattern
- Model: The Model represents the data and the business logic of the application. It is responsible for retrieving, processing, and managing data. It also defines how the data interacts with the rest of the system. For example, in an e-commerce application, the Model might include objects like Product, Order, or Customer, along with their behaviors and relationships.
- View: The View is responsible for presenting the data to the user. It is the user interface (UI) component of the application. The View relies on the Model to retrieve data and displays it in a way that makes sense to the user. For instance, a View might consist of HTML templates, graphical user interface components, or any other medium through which users interact with the application.
- Controller: The Controller acts as a mediator between the Model and the View. It processes user inputs, interacts with the Model to retrieve or modify data, and determines which View should be displayed. Essentially, the Controller orchestrates the flow of data and user interactions in the application.
How MVC Works: A Practical Example
To illustrate how the MVC pattern operates, let’s consider a simple example of a blog application.
- Model: The Model could represent entities like
- View: The View might be a web page that displays a list of blog posts or a form that allows users to create a new post.
- Controller: The Controller listens for user actions, such as clicking a "Submit" button to add a new blog post, and interacts with the Model to save the post. It then selects the appropriate View to display confirmation or updated information to the user.
For instance, when a user submits a new blog post:
- The Controller receives the form data and validates it.
- If valid, the Controller updates the Model by saving the new post to the database.
- The Controller then selects a View to inform the user that the post was successfully created, displaying it in the list of posts.
Use Cases:
- Web frameworks (e.g., Django, Ruby on Rails).
- GUI applications.
Pros:
- Promotes separation of concerns.
- Simplifies parallel development of UI and backend logic.
Cons:
- Overhead due to managing three components.
- Can become complex for large applications.
The Model-View-Controller (MVC) architectural pattern has stood the test of time as a robust, flexible, and scalable approach to software design. By separating concerns into distinct components, MVC not only promotes clean and maintainable code but also enables teams to work more efficiently.
While it may not be the perfect fit for every project, understanding and mastering MVC is an essential skill for any developer. Whether you’re building a small application or a large enterprise system, the MVC pattern provides a solid foundation for creating software that is both reliable and adaptable to future changes.
Blackboard Pattern
At its core, the Blackboard pattern revolves around a shared knowledge base (the "blackboard") that acts as the central communication hub for various independent modules or components, often referred to as knowledge sources. These knowledge sources operate independently, contributing their specialized expertise to the blackboard when they detect opportunities to progress toward a solution. The system iteratively refines the solution, with each component building upon the contributions of others.
This pattern is particularly valuable in situations where the solution space is not well-defined, and no single algorithm or process can solve the problem in isolation. Instead, multiple components collaborate asynchronously, leveraging their unique strengths to incrementally reach a resolution.
Blackboard Pattern
Architectural Structure of the Blackboard Pattern
The Blackboard pattern consists of three key components:
- The Blackboard: The blackboard serves as the central repository where data, intermediate results, and final solutions are stored. It is the primary means of communication between the knowledge sources, ensuring that all components have access to the latest state of the problem.
- Knowledge Sources (KS): These are specialized, independent modules or agents that contribute to solving the problem. Each knowledge source has a specific area of expertise and operates autonomously. They monitor the blackboard for changes and decide when to act based on their own triggering conditions.
- Control Mechanism: The control mechanism oversees the overall process, deciding which knowledge sources to activate and in what order. It ensures that the system progresses efficiently by managing the interactions between the blackboard and the knowledge sources.
The interaction among these components is dynamic and asynchronous, allowing the system to adapt to changing problem states and incorporate incremental improvements.
Use Cases:
The Blackboard pattern is well-suited for scenarios where collaboration among diverse components is critical. Some notable applications include:
- Artificial Intelligence (AI) Systems: Early AI systems, such as speech recognition, natural language processing, and image interpretation, often relied on the Blackboard pattern. These systems required multiple specialized modules (e.g., phoneme recognition, syntax analysis) to work together in tackling complex tasks.
- Robotics: In robotics, the Blackboard pattern facilitates communication between various subsystems, such as perception (e.g., vision, sensors), planning, and control. Each subsystem contributes its expertise to achieve coordinated actions.
- Real-Time Systems: Real-time systems, such as air traffic control or autonomous vehicles, use the Blackboard pattern to integrate data from multiple sources (e.g., radar, sensors) and make decisions dynamically.
- Data Fusion Systems: The pattern is frequently used in data fusion applications, where information from disparate sources (e.g., satellite data, ground sensors, and weather reports) needs to be combined to generate a comprehensive understanding.
- Problem-Solving in Scientific Research: Scientific applications, such as protein folding or astronomical data analysis, benefit from the Blackboard pattern's ability to coordinate contributions from independent computational models.
Despite its origins in early AI and expert systems, the Blackboard pattern continues to find relevance in modern software development. Its modular and collaborative approach aligns well with contemporary challenges, such as integrating machine learning models, managing distributed systems, and solving interdisciplinary problems.
As technology evolves, the value of architectural patterns like the Blackboard lies in their ability to adapt and remain applicable to new contexts. By facilitating collaboration among specialized components, the Blackboard pattern ensures that no single system operates in isolation, paving the way for innovative solutions to the world's most complex problems.
Pros:
- Suitable for complex problem-solving.
- Encourages collaboration among components.
Cons:
- Performance overhead for data synchronization.
- Difficult to design and implement.
The Blackboard architectural pattern embodies the essence of teamwork in software design. By creating a shared space where independent components can contribute their expertise, it enables systems to tackle problems that would otherwise be insurmountable. As a testament to its versatility and effectiveness, the Blackboard pattern remains a cornerstone of software architecture, proving that collaboration truly is the key to success.
Interpreter Pattern
The Interpreter Pattern is a behavioral design pattern that provides a way to evaluate sentences in a specific language. In essence, it defines a grammar for a language and then interprets sentences or expressions written in that language. The Interpreter Pattern is most commonly used in scenarios where there is a need to process and evaluate structured input, such as mathematical expressions, configuration files, or domain-specific languages.
This pattern is particularly powerful because it simplifies the process of interpreting expressions by encapsulating the grammar rules and evaluation logic into separate classes. By using a set of well-defined operations, the pattern promotes code reuse and makes it easier to extend the grammar as new requirements emerge.
Interpreter Pattern
Key Components of the Interpreter Pattern
The Interpreter Pattern consists of several key components that work together to process and evaluate input:
- Abstract Expression: This defines the interface for interpreting expressions. It is typically implemented as an abstract class or interface.
- Terminal Expression: Represents the simplest elements of the grammar, such as individual variables or constants. Terminal expressions do not contain further sub-expressions.
- Non-Terminal Expression: Represents complex expressions composed of terminal and/or other non-terminal expressions. These are typically recursive in nature, adhering to the grammar's rules.
- Context: Provides the external information or environment required during the interpretation process, such as variable values or any additional input.
- Client: The client is responsible for constructing the abstract syntax tree (AST), which represents the structure of the input expression. Once constructed, the client uses the AST to interpret the expression.
How the Interpreter Pattern Works
To understand how the Interpreter Pattern works, consider a simple example: evaluating mathematical expressions like 3 + 5 - 2. The process typically involves the following steps:
- Parsing Input: The input string is parsed to identify the structure of the expression. This may involve tokenizing the input and creating the abstract syntax tree.
- Constructing the AST: The abstract syntax tree is built, with terminal expressions representing constants (e.g.,
- Evaluating the AST: The AST is traversed, and the interpretation logic is applied at each node to compute the final result.
For example, the AST for 3 + 5 - 2 would look like this:
(-)
/ \
(+) 2
/ \
3 5Each node of the tree is evaluated recursively, starting from the leaves (terminal expressions) and moving up to the root.
Applications of the Interpreter Pattern
The Interpreter Pattern has a wide range of applications across various domains. Some of the most common use cases include:
- Language Parsing: The pattern is ideal for implementing parsers and interpreters for domain-specific languages (DSLs). For instance, configuration files with custom syntax can be processed using an interpreter.
- Expression Evaluation: It is frequently used for mathematical and logical expression evaluation, especially in calculators and scientific software.
- Rule Engines: The pattern is well-suited for implementing business rule engines where rules are expressed in a declarative format and need to be evaluated dynamically.
- Data Transformation: The Interpreter Pattern can be applied to transform or validate structured data, such as XML or JSON, based on predefined rules.
- Query Processing: Database query languages, like SQL, can benefit from this pattern by parsing and interpreting queries.
Use Cases:
To put the Interpreter Pattern into perspective, let’s explore a few real-world examples:
- Math Expression Evaluators: Many scientific calculators use the Interpreter Pattern to evaluate user-input mathematical expressions.
- Game Scripting: Video games often use domain-specific scripting languages for defining character behaviors, game rules, or level designs. The Interpreter Pattern is a natural fit for processing these scripts.
- Regular Expressions: Regular expression engines use a similar approach to parse and evaluate patterns against input text.
- Programming Language Interpreters: Popular programming languages like Python or JavaScript include interpreters that rely on similar principles to process and execute code.
Pros:
- Simplifies language parsing.
- Flexible for various use cases.
Cons:
- Limited scalability for large datasets.
- Can be slow compared to compiled solutions.
The Interpreter Pattern is a valuable addition to the toolkit of any software architect or developer working with rule-based systems, language processing, or expression evaluation. While it has its limitations, its modularity, clarity, and focus on grammar-driven interpretation make it an elegant solution for many problems.
Understanding when and how to apply the Interpreter Pattern can significantly enhance the flexibility and maintainability of your software architecture. By thoughtfully implementing this pattern, you can create systems that are not only robust but also adaptable to change, ensuring long-term success in an ever-evolving software landscape.
Comparison of Architectural Patterns
Here’s a quick summary of how these patterns stack up:
| Pattern | Use Case | Pros | Cons |
| Layered | Web apps, enterprise systems | Clear separation of concerns | Performance overhead |
| Client-Server | Online apps, banking | Centralized control | Server dependency |
| Master-Slave | Databases, peripherals | Parallel processing | Single point of failure |
| Pipe-Filter | Data processing, compilers | Modularity | Increased latency |
| Broker | Distributed systems, microservices | Decoupling | Performance bottleneck |
| Peer-to-Peer | File sharing, blockchain | Fault tolerance | Security vulnerabilities |
| Event-Bus | Notifications, UIs | Loose coupling | Debugging complexity |
| MVC | Web frameworks, GUIs | Code reusability | Overhead |
| Blackboard | AI, robotics | Collaboration | Synchronization overhead |
| Interpreter | DSLs, query languages | Simplified parsing | Limited scalability |
Summary
Software architectural patterns provide a structured approach to solving common design challenges. By carefully choosing the right pattern for your project, you can ensure scalability, maintainability, and performance. Whether you're building a distributed system, a real-time application, or a traditional web app, understanding these patterns will empower you to make informed architectural decisions.
Last Update: 01 Feb, 2025